
‘AI 3강’을 목표로 내건 국내 소버린 인공지능(AI) 전략이 기초 학문 추론 능력이라는 관문조차 넘지 못하고 있다는 경고음이 나왔다. 해외 AI가 수능 수학과 고난도 논술 문제에서 이미 ‘의대 합격선’에 해당하는 성적을 받은 반면, 국내 AI는 다수 모델이 낙제점에 머물면서 “여전히 재수를 고민해야 할 수준”이라는 평가가 제기된다.
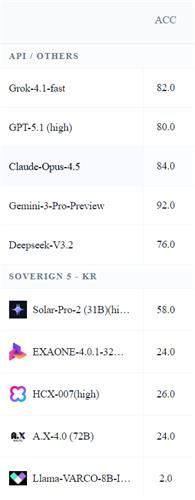
15일 김종락 서강대 수학과 교수 연구팀에 따르면, 국내 ‘국가대표 AI’ 도전 5개 팀의 주요 대형언어모델(LLM)과 오픈AI·구글·xAI·앤트로픽·딥시크 등 해외 AI 5개 모델을 대상으로 수능 수학 20문제와 논술 30문제를 풀게 한 결과, 해외 모델은 76~92점, 국내 모델은 최고 58점에 그쳤다.
연구팀은 수능 문제로 공통과목, 확률과 통계, 미적분, 기하 영역에서 가장 난도가 높은 문항 5개씩을 선별했다. 논술은 국내 주요 대학 기출 10문제와 인도 대학 입시 10문제, 일본 도쿄대 공대 대학원 입시 수학 10문제로 구성했다. 총 50개 문제를 10개 AI 모델에 풀게 한 것이다.
해외 모델 가운데서는 구글 ‘제미나이 3 프로 프리뷰’가 92점으로 가장 높은 점수를 기록했고, GPT-5.1, 클라우드 오푸스 4.5, 그록 4.1 패스트, 딥시크 V3.2 등도 모두 70~90점대 성적을 받았다. 반면 국내 모델은 업스테이지의 ‘솔라 프로-2’가 58점으로 가장 높았고, LG AI연구원의 ‘엑사원 4.0.1’, 네이버 ‘HCX-007’, SK텔레콤 ‘A.X 4.0’ 등은 대부분 20점대에 머물렀다. 엔씨소프트의 경량 모델 ‘라마 바르코 8B 인스트럭트’는 2점으로 최저점을 기록했다.
연구팀은 국내 모델들이 단순 추론만으로는 문제를 거의 풀지 못해 파이선 계산 툴 사용까지 허용했지만 성적 개선은 제한적이었다고 설명했다. 이는 계산 능력보다 문제 구조를 이해하고 논리를 전개하는 기초 수학 추론 역량 자체가 부족했음을 보여준 결과라는 분석이다.
격차는 연구팀이 자체 개발한 고난도 수학 문제 세트 ‘엔트로피매스(EntropyMath)’에서도 반복됐다. 대학생 수준부터 교수급 논문 연구 난이도로 구성된 문제 10개를 풀게 한 결과, 해외 모델은 82.8~90점을 기록한 반면 국내 모델은 7.1~53.3점에 그쳤다. 세 차례 도전 기회를 주는 방식에서도 해외 모델은 대부분 90점 이상을 기록했지만, 국내 모델은 20~70점 수준에 머물렀다.
이에 대해 LG AI연구원은 평가 방식에 문제를 제기했다. LG 측은 “엑사원 4.0.1은 추론 기능을 활성화하기 위한 특정 프롬프트가 필요한 모델”이라며 “모델 특성을 고려하지 않은 시험”이라고 반박했다. LG AI연구원이 자체 방식으로 동일 수능 문제를 시험한 결과 평균 88.75점이 나왔다는 주장도 내놨다.
정부와 업계는 이번 결과가 국내 AI 기술의 ‘한계’를 단정짓는 것은 아니라는 입장이다. 배경훈 부총리 겸 과학기술정보통신부 장관은 “국내 기업들은 그동안 산업·서비스 목적의 AI 개발에 집중해 왔고, 수학·과학 추론에 특화된 학습 데이터가 부족했던 것이 사실”이라며 “도메인별 특화 데이터와 학습 전략을 강화하면 글로벌 톱 수준 경쟁력도 가능하다”고 말했다.
김종락 교수는 “국내 모델은 기존 공개 버전을 기준으로 평가한 만큼, 각 팀의 국가대표 AI 버전이 공개되면 자체 개발 문제로 다시 성능을 검증할 계획”이라며 “엔트로피매스를 기반으로 한 수학 리더보드를 국제적 수준으로 키워 수학뿐 아니라 과학·제조·문화 영역까지 도메인 특화 AI 성능 개선에 기여하겠다”고 밝혔다.


![12연패 vs 8연패, 프로야구 연패·연승이 미치는 영향 [해시태그]](https://img.etoday.co.kr/crop/140/88/2340870.jpg)
![한화에어로 폭발 사고로 5명 사망…경영진 직접 브리핑 나선다 [종합2보]](https://img.etoday.co.kr/crop/140/88/2340707.jpg)
![쉽지 않은 내 집 찾기…평균 2.4개월ㆍ3.8곳 둘러보고 계약한다 [데이터클립]](https://img.etoday.co.kr/crop/140/88/2340884.jpg)
![젠슨 황 “베라 루빈 본격 생산 단계”…삼성·SK하닉 메모리 탑재 [컴퓨텍스2026]](https://img.etoday.co.kr/crop/140/88/2340757.jpg)

![5월 수출 878억달러로 53%↑'역대 최대'⋯슈퍼사이클 반도체 '주도' [종합]](https://img.etoday.co.kr/crop/140/88/2331023.jpg)



![평균 연봉 5천이라는데 내 월급은 왜 이럴까? 아무도 말 안 하는 진짜 현실 연봉 [T같은F]](https://i.ytimg.com/vi/xFoKkSaS9s0/mqdefault.jpg)




![테트라팩 코리아, 2026 난빛축제 '성료' [포토]](https://img.etoday.co.kr/crop/85/60/2340914.jpg)




![대전 한화에어로스페이스 공장 폭발 사고… 5명 사망·2명 부상 [종합]](https://img.etoday.co.kr/crop/85/60/2340698.jpg)
![쉽지 않은 내 집 찾기…평균 2.4개월ㆍ3.8곳 둘러보고 계약한다 [데이터클립]](https://img.etoday.co.kr/crop/300/170/2340884.jpg)
![여름철 외식물가 '껑충'…냉면·삼계탕도 부담 [포토]](https://img.etoday.co.kr/crop/300/190/2340901.jpg)